Self applicability
Jun 10, 2017 — Tags: Project motivation
Self applicability is one of the most powerful ideas in computer science. In this article we’ll see how this idea can be applied to Expressions of Change such as Version Control, and how this compares to existing solutions such as Git.
We’ll take a look at the practice of rewriting history, why we would want to do that and how it creates two seemingly irreconcilable goals: staying true to what actually happened on the one hand and the ability to tell the most clear story about history on the other. Then we’ll see how we can reconcile these goals by applying the idea of version control to version control itself.
Editing Programs
To be able to properly discuss all this, we’ll start at the very beginning: by examining some very minimal examples of the construction of a computer program.
To describe these, we’ll use pen, paper, an eraser and a pair of scissors - this way everything stays simple and visual. Note that this description is no less general than the usual process of constructing programs on an actual computer: wherever we talk about “pieces of paper”, we can simply substitute “one or more files”.
Say that on a given Monday we’re given the task to write a simple program. We do so by writing this on our piece of paper and call it a day.
At some point soon after, let’s say on Tuesday, the need arises for a more advanced program. We erase part of our program and add some new parts to reflect this, like so:

Now, if we discover a bug in our program on Wednesday, we’re faced with a problem: we cannot simply go back to Monday’s version of the program, because it no longer exists. Nor can we compare Monday and Tuesday’s versions to reason about them.
This is caused by the fact that changing the program brings with it the loss of information. This is particularly obvious in our example because we’re literally erasing part of the first program to write the second. Note however that even if we only ever add to the program, we destroy the knowledge of what the program looked like before the additions.
Version Control
To be able to keep the old versions around we could use a modern Version Control System such as Git. In addition to the ability to go back or forward to an arbitrary version of the program, this will allow us to compare versions, work together with other people and merge diverging lines of development.
In our pen & paper world we will model Version Control by using an extra piece of paper. On this we draw the versions of the program as nodes, annotate these with some meta-data (date, author, description), and connect them by arrows into a directed acyclic graph that describes the history of the program.
The graph may be constructed by copying a given current state of the program over to this second piece of paper and adding the relevant metadata. This corresponds to a git commit.
We can then navigate through this graph by pointing at a given node with our finger (below: a big red arrow), and copying the node’s content over into the current program state. This corresponds to a git checkout. Because we always have the full history available, we’ve solved our initial problem!

Rewriting History
An important value for a historic record is its historic accuracy: the fact that it precisely reflects what actually happened. In Version Control as discussed so far, historic accuracy is guaranteed by the means of construction of the historic record. There are various versions of the program, and they each get added to the graph as they are created.
In the toy example above we established the need for Version Control by talking about a simple means of going back in time. In larger projects, the historic information becomes more than a simple time machine: it becomes a repository of knowledge about the history of the project, offering insight in questions of intent. This value is further enhanced by best practices such as writing meaningful descriptions for each version and ensuring a single version contains only a single set of related changes. In the light of this role, another value for a historic record emerges: the clarity of the record - records that are more clearly understandable by users being better than ones that are hard to understand.
Sometimes the values of accuracy and clarity are at odds with each other: most clear story about history is not told by the description of history as it actually happened, but rather by some simplification or cleanup. In such cases a may be useful to rewrite history. Here are some examples of such rewrites with their equivalent git commands:
-
If you make a mistake while adding a version to the historic record, you may want to fix the mistake in the record rather than adding yet another version to fix the mistake (such a version would only clutter the record). (
git commit --ammend) -
History is not always linear; multiple new version may arise based on a single version of the program. Such diverging histories can later be merged together in a separate “merge” version. However, many such separate version will clutter up the historic record, and are therefore sometimes deemed undesirable. The solution is to rewrite history as if the divergence never took place: one of the diverging branches of history is cut from its actual base, rewritten, and pasted at the tail of the other branch in a single linear fashion. (
git --rebase -i)
An animation of a git rebase in our pen & paper world is shown below: the commit “C” is rewritten as if it happened after “B”, rather than independently of it; this simplifies the graph because we no longer need a merging commit.
As should be obvious from these two examples, rewriting of history can be quite helpful in increasing the clarity of the historic record by removing clutter in the form of irrelevant details. It does, however, come at a price; one which is hinted at by the use of scissors in the animation.
Firstly, it violates precisely the goals as stated in the initial example: a true historic record without loss of information. This is not merely a theoretical problem: consider the case of a rebased version which has some kind of bug. For such a bug it is impossible to say whether it was introduced as a direct consequence of the rebasing or was also present in the unrebased version. Given that such understanding is precisely what version control is about, this is really unfortunate.
Secondly, consider the fact that version control forms an important safety net in our software development process: when we make mistakes we can undo them by going back to an older version. However, while rewriting history we don’t have the capability of reverting mistakes made in the rewriting process itself. This is precisely why most blog articles about rewriting of history in Git are annotated with big red warning boxes.
So far we’ve seen two seemingly irreconcilable goals: “true history” and a “clear history”. Because the goals are presented as an either/or choice, striking some balance is left as a matter of culture or taste to individual users and teams. It has been my personal observation that users of Mercurial often err on the side of accuracy, whereas users of Git prefer clean histories, but your mileage may vary.
Self Applicable Version Control
The question that seems to remain unasked is: is it be possible to have a historic record that’s both truthful to what actually happened and a clear description that leaves out irrelevant details?
To answer this, let’s go back to the running example of keeping track of our program and the history of our program on a piece of paper. So far we’ve seen the following:
- The Program
- A piece of paper may be used to write a program.
- At some point new features are requested, and we must edit the program.
- Once we do this lose information about previous versions of the program.
- Version Control
- A piece of paper may be used to keep track of a historic graph of all programs from step 1.
- It may be useful to clean up this graph by rewriting history for reasons of clarity.
- Once we edit the historic graph we lose information about previous versions of the history.
We’ve seen that the problem mentioned in step 1c was solved by step 2a; and that we have an as of yet unsolved problem in step 2c. The question then is: can we think of a step 3a to solve this?
Sure: we can simply add yet another piece of paper containing a historic graph, just like we did in step 2a. The only difference being the content of the nodes of the graph: rather than keeping track of individual programs, we can track the history of historic graphs. Let’s call this graph a 2nd level history.
Construction of this graph is analogous to the construction of the regular historic graph: whenever we change the historic record, we add a full copy of the historic graph to the second-level history as a node. We do this both for any history writing operations (such as a git commit) as for rewriting operations (such as git rebase).
Just like in the case of regular Version Management we can navigate through the newly constructed graph. Navigation through a second level history corresponds to changes in the historic graph (rather than changes to the program). In other words: it corresponds to rewrites of history. Here it is in action:
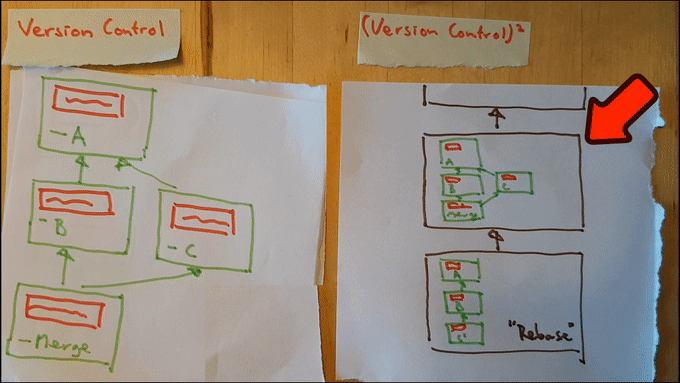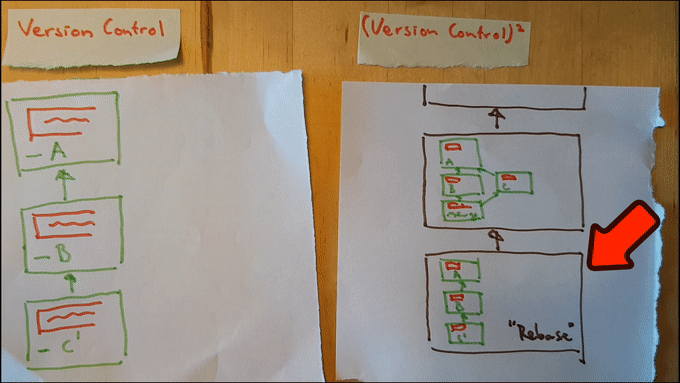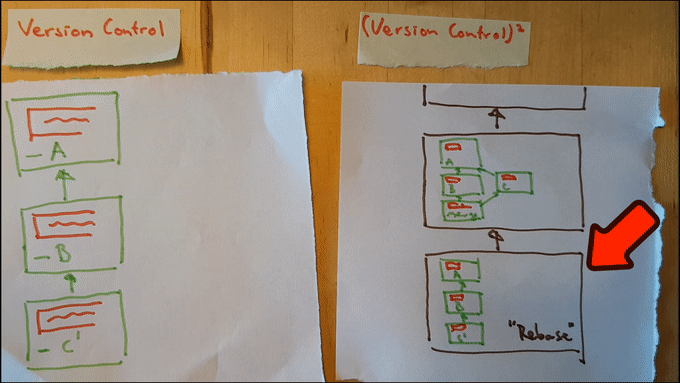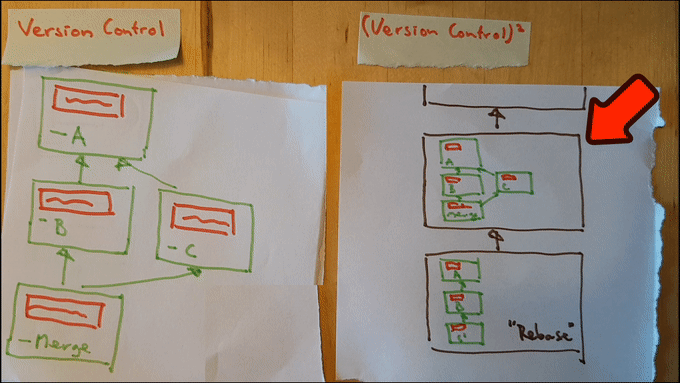
Note that we’ve achieved our goal now! We can rewrite our first level history to be as clear as possible, while keeping a record of precisely what actually happened available in our second level history. This gives us the ability to un-rewrite history just as easily as reverting back to a previous version of our program.
We did this simply by applying the idea of Version Control on itself: we use Version Control on graphs representing Version Control. This is hardly a unique idea in the field: other examples are using compilers to compile compilers and applying functions to functions to yield further functions.
Down the rabbit hole
Now that we’ve seen that the concept of tracking change is self-applicable, we may ask how often we may want to self-apply. Is it possible to talk about third or nth level histories, i.e. histories of histories of histories or even deeper levels? Secondly: is there any use for such expressions?
The first question is easily answered: yes, we can always keep adding more layers. Any Version Control which doesn’t care what’s under control can always be used to wrap an n - 1 level history to yield an n level history.
Now for the second question: are such deep self-applications of any use? To this, I do not yet know the answer.
In general, to get the advantages of Version Control in all parts of your system, you need precisely one more level of history than the amount of levels on which you want to make potentially destructive changes.
So far, we’ve seen that making of destructive changes on the first level of history (“rewriting history”) is occasionally quite useful, and that we may therefore want to introduce a second level of history.
Because we lack actual experience with such a second level history, use cases for destructively editing that have not yet shown themselves. It may be that they don’t actually exist; in which case we’re done. If they do, a third level might be useful. In any case, it would seem that for each level the amount of usage decreases, an that we at some point run out of the need for further levels.
Self-applicable Git
Implementing the above insights using a typical modern Version Control System such as Git does, unfortunately, not lead to very useful results.
This is caused by the following: In the above we made no assumptions about the nature of the pieces of paper - other than that they could be stored as a file on a computer.
Git and comparable systems, on the contrary, do make specific assumptions: most modern Version Control systems are built on the assumption that the files they are tracking are almost exclusively text files. Even though storing the occasional small binary file is certainly technically possible, storing large numbers of large binary files in Git is certainly not recommended, and will not lead to a workable system.
The Git repository itself is implemented precisely as a collection of binary files. This means that tracking the history of a Git repository cannot be done efficiently using Git.
In fact: trying this one runs into the fact that adding Git repositories to be tracked inside other repositories has been explicitly forbidden: git repositories are managed using a directory called .git, and Git raises an error when presented with a directory named .git to track.
Implementation hint
In the pen-and-paper examples of this article, the trackable items of interest (whether computer programs or complete n-histories) were always presented as files. Tracking such files was presented as adding the full state at any given point in time as a historic node to the graph.
This approach does not generally scale to n-level histories: the storage requirements at each level grow like so:
- the 1-history stores all programs, i.e. growth linearly with program size and version count.
- the 2-history stores all 1-histories, i.e. growth linearly with [1] and version count.
In this approach, the storage requirements for a given n-history’s are O(p * vn). (p for program size, v for number of stored versions and n for n-level-history)
An important observation is that the actual (human) user actions that give rise to this growth is much more limited. The actual things the user can do are limited to:
- Make direct changes to the program.
- Calling various commands of (a n-level) Version Control system
If we only store such user-actions into the various levels of Version Control, we’ll get a system that scales linearly with user input.
Next steps
In this article I’ve shown (hopefully) how applying the ideas of Version Control on their own data-structures can be quite useful.
We’ve also seen that having the property of self-applicability is not a given - e.g. Git cannot meaningfully be applied on Git repositories.
I expect to be adding some example programs to this site at some point in the future. Inasmuch as those programs will be like Version Control systems, the ability to self-apply is an important design goal.